This is a course for PyTorch and it will be helpful for those who wants to make a career in Machine Learning. This course comes with a 30 day money-back guarantee, so if you are not satisfied within this period, you can get your money back. This is the best course on Machine Learning you will find online, as it is highly rated and comes with a certificate of completion. The course also includes lifetime access at no extra cost.
What Is PyTorch?
Python is a machine learning library that supports tensor computation and deep neural networks. Facebook’s artificial intelligence group developed this engine, which is typically used to run deep learning frameworks. Through the use of GPUs, it offers maximum performance for developers. The tool replaces NumPy and allows the construction of dynamic computation graphs rather than TensorFlow’s static computation graph. This tool allows users to build deep neural networks and process more data efficiently.
Why you need to Learn PyTorch
Big data’s increasing importance as a source of critical insights could make deep learning frameworks an essential part of your data science career. The entire system remains open-source, and all code and documentation are maintained on GitHub. Unlike other natural language processors, it is entirely written in Python. You can build deep learning models quickly with this program, perform automatic differentiation and code testing, and build deep learning models in real-time. Although TensorFlow continues to dominate the industry, PyTorch is gaining traction due to its dynamic nature.
Launch a Career in AI with PyTorch
The technology industry is continually evolving for the purpose of keeping organizations competitive and relevant. With a good grasp of the libraries that make deep learning possible, you can help your organization implement tech initiatives successfully. You can put yourself ahead of the competition by developing a broad knowledge of many deep learning libraries, including PyTorch and TensorFlow. You can bring real value to the organization by predicting events and giving it an edge over the competition. Using PyTorch as a deep learning platform, you can deploy critical models to make better predictions, provide more insights, and take advantage of big data for the first time. In addition to your valuable business and research contributions, you can also ignite your career by helping humanity solve persistent problems.
Why you need Pyrtorch for Deep Machine Learning
Python is the language used in PyTorch.
Data scientists and deep learning engineers most often use Python as a coding language. However, Python continues to enjoy popularity among academics as well. The PyTorch creators aimed to provide a great deep learning experience for Python, and Torch was born from this. Hence PyTorch was born as an open-source deep learning and machine learning library built on Python.
Graph Computation With A Dynamic Approach
Python uses dynamic graphs as the foundation for deep learning applications that can be tested in real-time. Many popular deep learning frameworks operate with static graphs, meaning that the computational graphs must be created in advance. The user is not able to view what the GPU or CPU is doing when processing the graph. In contrast, PyTorch allows users to access all levels of computation and peak at any level.
Easier To Learn And Simpler To Code
As PyTorch maintains a close resemblance to many conventional programming practices, it makes it much easier to learn than other deep learning libraries. PyTorch also has superb documentation and is a great help for beginners.
Small Community of Focused Developers
Despite being a smaller community of developers than some other frameworks, PyTorch enjoys a haven at Facebook. The creators are given much-needed flexibility and freedom to work on bigger problems rather than optimizing smaller parts. The focused group of developers at PyTorch has helped the project achieve more success in the field.
Simplicity and transparency
Developers and data scientists benefit from transparency in the data graph. PyTorch’s steep learning curve makes creating deep neural networks much easier than TensorFlow’s.
Hybrid Front-End
Besides PyTorch’s new hybrid front-end, it provides a new set of features. The engine operates in two modes: eager mode and graph mode. In most cases, we use the eager mode for research and development since it is flexible and easy to use. The graph model is used in production because it accelerates processing and is optimized for optimal output.
Useful Libraries
Several tools and libraries have been developed for extending PyTorch. In addition to computer vision, the community offers support for other research areas such as reinforcement learning. This will allow PyTorch to better serve both research and production needs as a deep learning library.
Cloud support
Several major cloud platforms have also successfully adopted PyTorch, allowing developers to do large-scale training with GPUs. The cloud support of PyTorch enables models to be run in production environments as well.
Easy To Debug
It’s easier to use many popular Python tools in PyTorch since its computational graph is defined at runtime. PyTorch code can now be debugged using all of our favourite Python debuggers, such as PDB, IPDB, and PyCharm.
Data Parallelism
PyTorch contains a powerful feature known as declarative data parallelism. With this feature, you can wrap any module in Torch.nn.DataParallel. Using this feature, you can leverage multiple GPUs easily by parallelizing this over batch dimensions.
Pytorch Tutors on AssignU
You can get in touch with expert Pytorch tutors, developers, and engineers. With AssignU, you can find Python online help for coding problems, learning new technologies, and asking programming questions.
What do you learn from us?
With AssignU, you can apply important theoretical concepts in practical ways. We allow you to show code alongside explanations to explain concepts in an understandable manner. We will also provide you with our slides, which illustrate theory using clear visualizations.
You can get started with deep learning with Pytorch with our help. We offer the following topics for learning:
- Find out how to format data with NumPy for arrays.
- Data cleaning and manipulation using pandas
- Learn the principles of classical machine learning theories
- Deep learning with PyTorch libraries for image classification
- Using Python and Recurrent Neural Networks to analyze data from sequence time series
- Design Deep Learning models that can be applied to tabular data.
Embrace Deep Learning with PyTorch today and discover its true potential. If you need help with Pytorch assignments, you can rely on our services.
GRAMMARLY REPORT
Pytorch Ignite
Let’s learn about a popular new deep learning framework called Pytorch. The name is inspired by the popular Torch Deep Learning Framework written in the Lua programming language learning. Learning Lua is a big barrier to entry if you’re starting to learn deep learning. It doesn’t offer the modularity necessary to interface with other libraries like a more accessible language would. So a couple of AI researchers who were inspired by Torch’s programming style decided to implement it in Python, calling it high Pytorch. They also added a few other cool features to the mix. And we’ll talk about the two main ones.
Imperative Programming
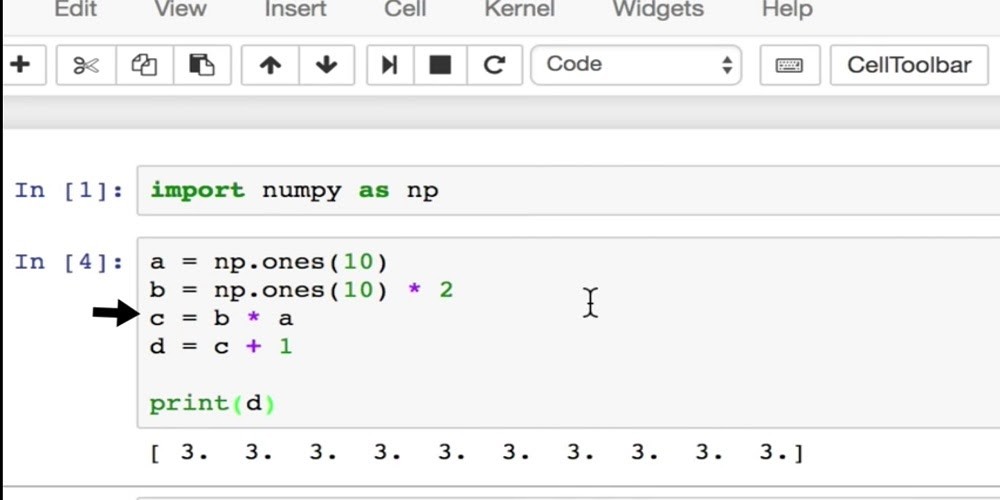
The first key feature of Pytorch is Imperative Programming. An Imperative Program performs computation as you typed it. Most Python code is imperative. In this NumPy example, we write four lines of code to ultimately compute the value for d. When the program executes C equals B times, it runs the actual computation then and there, just like you told it to.
In contrast, there is a clear separation between defining the computation graph and compiling it in its symbolic program. If we were to rewrite the same code symbolically and when C equals B times A is executed, no computation occurs at that line. Instead, these operations generate a computation or symbolic graph, and then we can convert the graph into a function that can be called via the compile step.
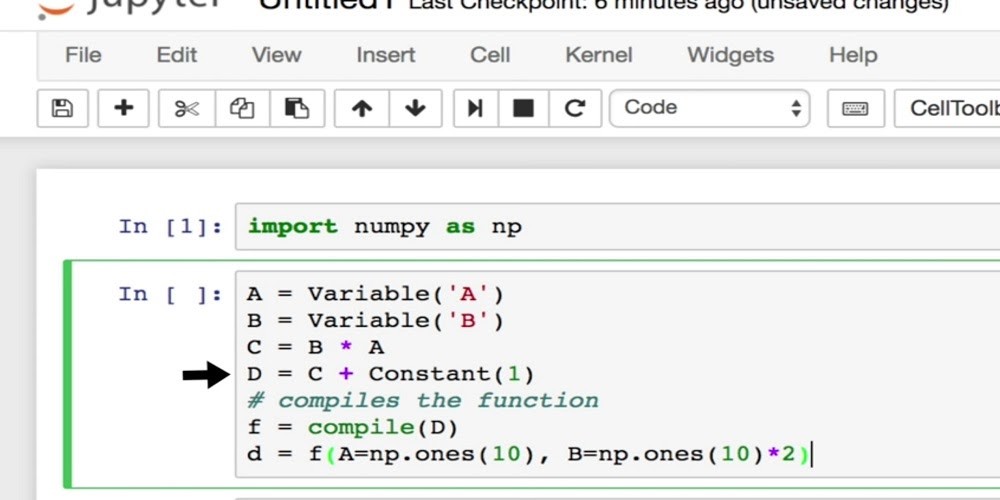
So computation happens as the last step in the code. Both styles have their trade-offs. Symbolic programs are more efficient since you can safely reuse the memory of your values for in-place computation.
Tensorflow is made to use symbolic programming. Imperative programs are more flexible since Python is most suited for them. So you can use native Python features like printing out values in the middle of computation and injecting loops into the computation flow itself.
Dynamic Computation Graphs
The second key feature of Pytorch is dynamic computation graphing as opposed to static computation graphing. In other words, Pytorch is defined by run. So at runtime, the system generates the graph structure. Tensorflow is defined and run where we define conditions and iterations in the graph structure. It’s like writing the whole program before running it. So the degree of freedom is limited. So in Tensorflow, we define the computation graph once, then we can execute that same graph many times. The great thing about this is that we can optimize the graph at the start. Let’s say in our model, we want to use some strategy for distributing the graph across multiple machines. This computationally expensive optimization can be reduced by reusing the same graph. Static graphs work well for neural networks that are fixed size, like feed forward networks or convolutional networks. But for a lot of use cases, it would be useful if the graph structure could change depending on the input data, like when using recurrent neural networks. In this snippet, we’re using Tensorflow to unroll a recurrent network unit over word vectors. To do this, we’ll need to use a special TensorFlow function called While Loop. We have to use special nodes to represent primitives like loops and conditionals because any control flow statements will run only once when the graph is built.
But a cleaner way to do this is to use dynamic graphs instead, where the computation graph is built and rebuilt as necessary at runtime. The code is more straightforward since we can use standard for and if statements. Any time the amount of work that needs to be done is variable, then Democrats are useful. Using dynamic graphs makes debugging easy since a specific line in our written code is what fails as opposed to something deep under section run. Let’s build a simple two-layer neural network in Pytorch to get a feel for the syntax. We start by importing our framework and the auto grab package, which will let our network automatically implement backpropagation.
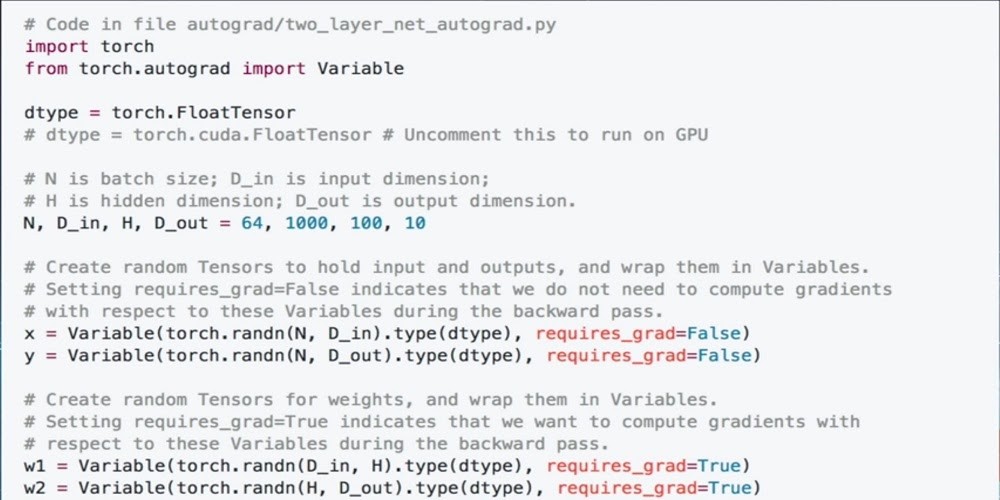
Then we’ll define our batch size, input dimension, hidden dimension, and output dimension. We’ll then use those values to help define Tensas to hold inputs and outputs. Wrapping them in variables well set requires gradients to be false. Since we don’t need to compute gradients with respect to these variables during backpropagation, the next set of variables will define our weights. Well, initialize them as variables as well, storing random Tensas with the data type. And since we do want to compute gradients with respect to these variables, we’ll set the flag to true. We’ll define a learning rate, and we can begin our training loop for 500 iterations.

During the forward pass, we can compute the predicted label using operations on our variables. MM stands for Matrix Multiply and clamps, clamps all the elements in the input range into a range between Min and Max.
Once we’ve matrix multiplied for both sets of weights to compute our prediction, we can calculate the difference between them and square the sum of all the squared errors. A popular loss function. Before we perform backpropagation, we need to manually zero the gradients for both sets of weights. Since the great buffers have to be manually reset before fresh grades are calculated. Then we can run backpropagation by simply calling the backward function on our Loss. It will compute the grading of our Loss with respect to all variables we set that require gradient to be true, for then we can update our weights using gradient descent and our outputs to look great. Pretty tough.
Conclusion
To sum up, Pytorch offers two really useful features: Dynamic Computation graphs and imperative programming. Dynamic computation graphs are built and rebuilt as necessary at runtime, and imperative programs perform computation as you run them. There is no distinction between defining the computation graph and compiling. Right now, Tensorflow has the best documentation on the web for a machine learning library. So it’s still the best way for beginners to start learning. And it’s best suited for production use since it was built with distributed computing in mind. But for researchers, it seems like Pytorch has a clear advantage here. A lot of cool new ideas will benefit and rely on the use of dynamic graphs.